I’m following the advice in the docs around proxying to another service. In essence, I have a route /cors-proxy/* which allows me to fetch stuff from the client that’s out there on the web (I’ve detailed this setup on my blog). Here’s the lines from my netlify.toml
[[redirects]]
from = "/cors-proxy/*"
to = ":splat"
status = 200
force = true
This has worked great in a lot of ways. But now I am encountering a strange bug that—to the best of my knowledge—is resulting from something on Netlify’s side and not my own (maybe some weird rate-limiting thing?)
Background & Problem
What’s happening is in my client side JS, I have an array of like 10 image urls. On the client, i’m iterating through each one and fetching that image out on the internet. Because the images are on other domains, i can’t just do:
fetch("https://somedomain.com/path/to/image.png")
So I use the a server-side proxy (via netlify) that gets the image for me and returns it back. Given my netlify configuration described above, I can do this on the client:
fetch("/cors-proxy/https://somedomain.com/path/to/image.png")
This works well in a lot of scenarios. For example, in one of my uses cases, I’m fetching 85 images from out on the web and it’s working just fine (a screenshot from my console):

What’s strange is that for a specific scenario, this is failing.
What’s even more strange is that it works on localhost, but when i ship to prod on readlists.jim-nielsen.com it works for like the first three images, but then just starts failing on the other seven. Here’s an example screenshot from my console:
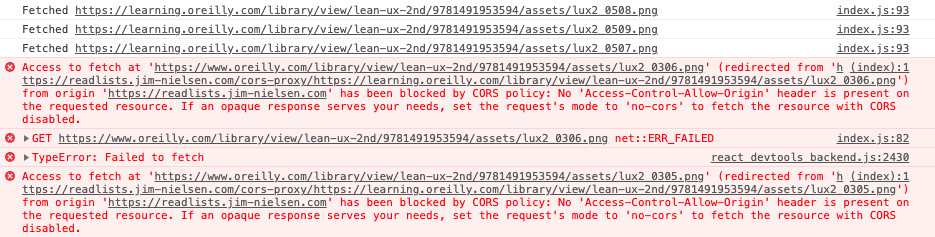
Note that the first couple images fetched just fine from the proxy, but subsequent ones failed due to CORS?
What’s even stranger is that, for a given URL that failed, if I run a fetch() on that same url right in the console, it works just fine:

Note in the screenshot above that the fetch("/cors-poxy/https://...") call failed when executing client-side code, but if I ran that same fetch right in my browser’s console fetch("/cors-proxy/https://...") it worked just fine.
Looking closer at the calls being made, the ones that succeed are giving back 200:

But the ones that fail are returning HTTP 302 with a location header that’s pointing to the image URL.

Additional notes:
- Doing a cURL on any of these images (ones that succeed with 200 and ones that fail with a 302 in the browser) results in no obvious difference. They all succeed with cURL.
- I’m using
netlify devon localhost, which (in theory) means it should work both locally and in prod. It’s strange that it works locally but when i put live on my URL some of those image fetches (not all) begin to fail.
Try It Yourself
You can try this yourself by visiting the live project: https://readlists.jim-nielsen.com/
Then import a readlist from this remote url: https://cdn.jim-nielsen.com/readlists/lean-ux.json

Then open your browser console and hit the “export to epub” link:

As an alternative test to see something working as expected, you can import this URL - https://cdn.jim-nielsen.com/readlists/shape-up.json - and hit “export to epub” and you’ll notice that it fetches all the images and everything works
Thoughts?
I can’t understand why this is failing. And not only failing, but only partially failing on some imges, but the proxy seems to continue to work for others.
 on this.
on this.




